
AI DATA SECURITY AND CLIENT CONFIDENTIALITY
An Introduction for Legal Professionals

Introduction
At a recent annual conference sponsored by the Idaho State Bar for Estate and Tax Attorneys, the topic of AI and ethical considerations—particularly client data and information security—took center stage. A few weeks later, an Arizona Bar technology working group similarly focused on AI and client confidentiality. In both cases, I was struck by what appeared to be a general lack of explanation, and therefore understanding, of the complexity of the AI pipeline among the legal community, including myself. This gap became especially apparent when attempting to determine what actual data protection measures were in place by various AI application providers, beyond just the Application Programming Interface (API) that we as professionals interact with.
To that end, I reached out to a few of the AI API providers I use seeking further clarification and understanding. I was not satisfied with the answers I received, so I embarked on my own journey to gain some insight and understanding. The following is meant to be a starting point for any professional concerned about data security as it relates to client documents, not a definitive statement of the technical minutia of machine learning, data science, and the AI stack. This article focuses solely on the topic of confidentiality and does not attempt to address management and oversight of AI tools and output.
Artificial intelligence tools like ChatGPT, Claude, Paxton, Grok, Perplexity, Spellbook, CiloAI, and similar large language models (LLMs) are increasingly becoming integral to the delivery of legal products. Attorneys use these tools to draft documents, research case law, summarize information and transcripts, analyze contracts, and perform various other applications. While these AI assistants offer unprecedented efficiency, they also introduce significant risks to client confidentiality that many practitioners do not fully understand.
The American Bar Association's Model Rule 1.6 requires attorneys to maintain client confidentiality and to make reasonable efforts to prevent unauthorized disclosure of client information. When you upload a client document to an AI service, that information leaves your control and enters a complex technical infrastructure owned and operated by third parties. Understanding this infrastructure is not just a matter of technological curiosity—it is an ethical imperative.
This article attempts to demystifies the AI query processing pipeline and explains where your client documents travel, identifies potential exposure points, and provides practical guidance for making informed decisions about AI tool usage. Visualizations accompany this article to help you understand these complex technical systems. References to the sources used to compile this information are provided.
The AI Query Processing Pipeline: The Journey of Your Client's Data
When you send a document to an AI service, it passes through ten or more distinct stages, each presenting potential security and confidentiality concerns. The visual on the following pages provides a simplified summary of the AI stack. [See Figure 1]
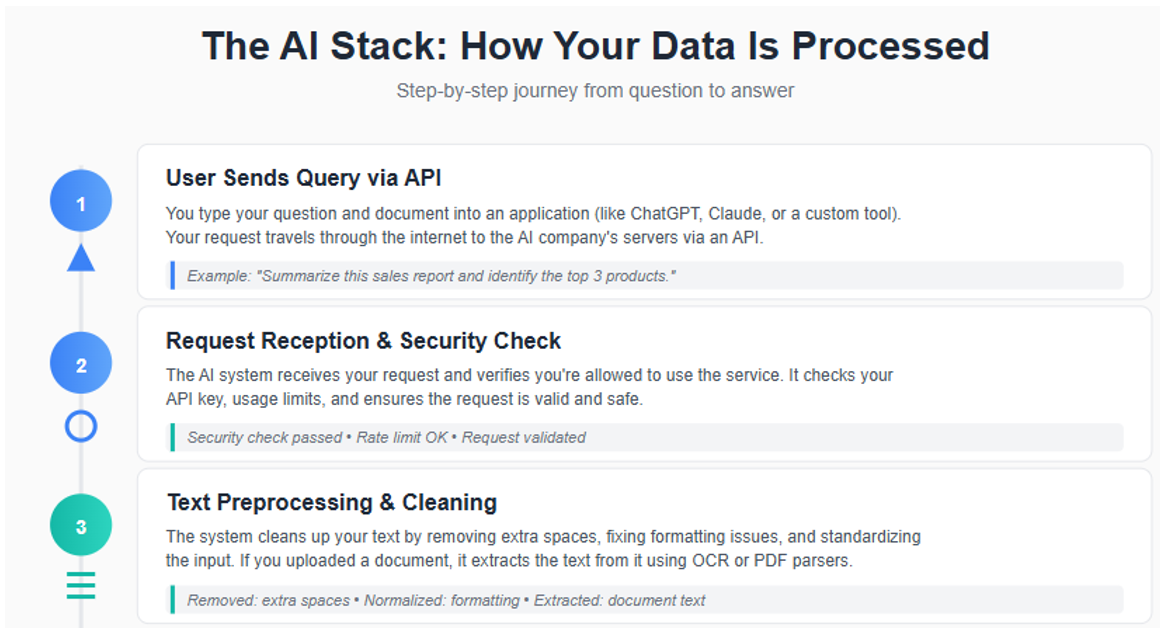
Stage 1-2: From Your Application to the AI Provider
Your interaction with AI begins within your chosen application—whether that is a cloud-based tool like Microsoft 365, a web browser accessing ChatGPT, a custom-built solution, or a legal practice management platform with AI features. Up until you grant access or upload a document, you retain full control over your information exposure to third-party APIs.
However, once your document is accessed or transmitted to an AI provider's servers (such as OpenAI for ChatGPT or Anthropic for Claude), control shifts away from you. Although encryption safeguards your data during transit, your document immediately enters infrastructure managed by external parties. At this stage, network logs may record metadata such as file size, timestamp, and your IP address, further extending the reach of your data beyond your direct oversight.
Stage 3-4: Document Storage and Processing
Stages 3 and 4 represent a critical exposure point for your client data. Your document is now stored on the AI provider's servers or on a third-party server with which the provider contracts.
Once your document reaches the AI provider's infrastructure, it may be temporarily stored in memory (RAM), cache systems such as Redis or Memcached, or short-term disk storage. If you submit a PDF, Word document, or image, the provider typically relies on third-party services—like AWS Textract, Google Cloud Vision, or Apache PDFBox—to extract the text content. As a result, your client's confidential information can traverse additional systems operated by major cloud vendors, further expanding the circle of exposure beyond your direct control.
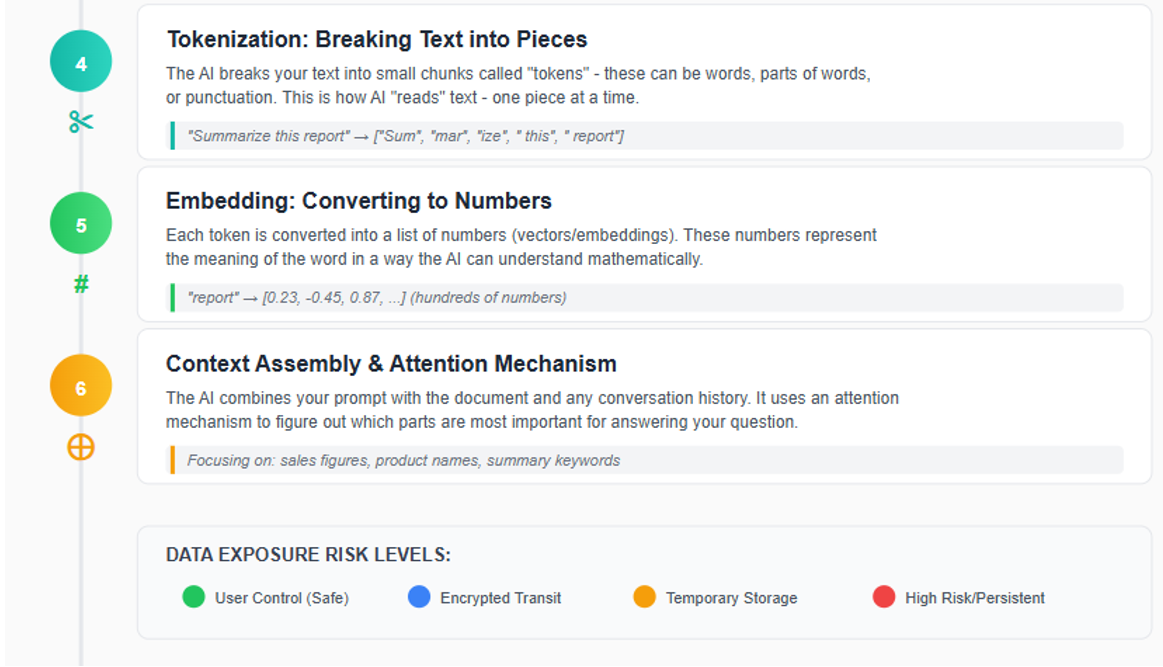
After extraction, the text undergoes a process called tokenization, where it is divided into small, machine-readable chunks. For instance, a simple instruction like "Summarize this contract" might be split into tokens such as ['Sum', 'mar', 'ize', ' this', ' contract']. The specific approach to tokenization, along with response generation parameters—including "temperature," which controls output randomness—are proprietary to each provider and form part of their intellectual property. These technical choices influence both the accuracy and confidentiality risks associated with AI-driven document processing.
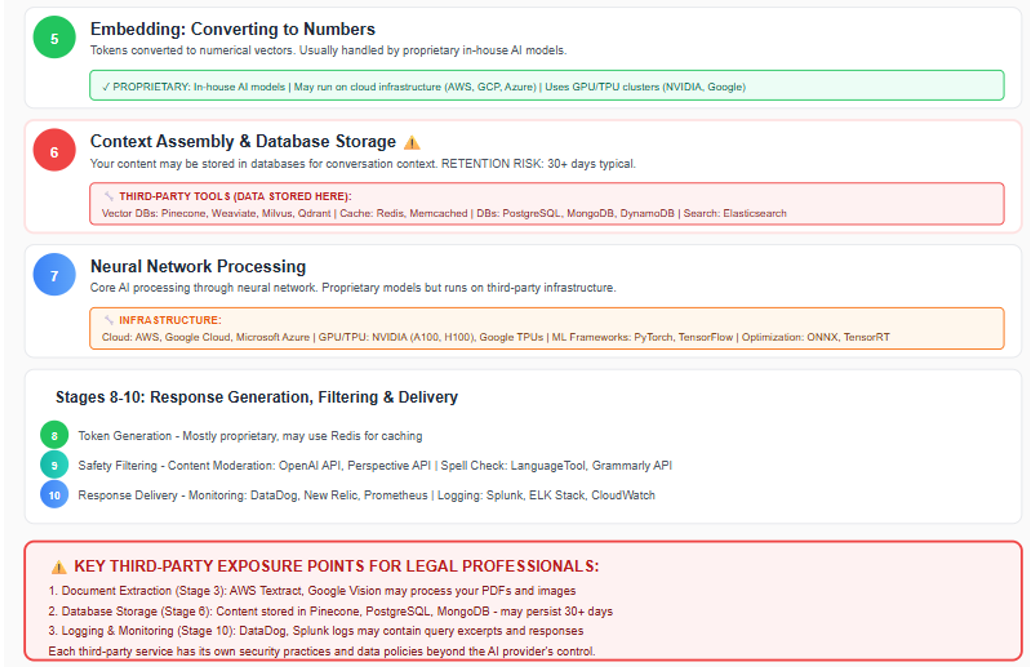
Stage 5-6: Database Storage and Context Assembly
Once your document enters the AI provider's infrastructure, it may be stored across several types of databases, each introducing distinct risks to client confidentiality. Common storage solutions include traditional databases—such as PostgreSQL or MongoDB—which are often used to retain conversation history. For more advanced features like semantic search and contextual retrieval, providers may utilize vector databases like Pinecone, Weaviate, or Milvus. Additionally, cache systems such as Redis are employed to optimize performance and speed.
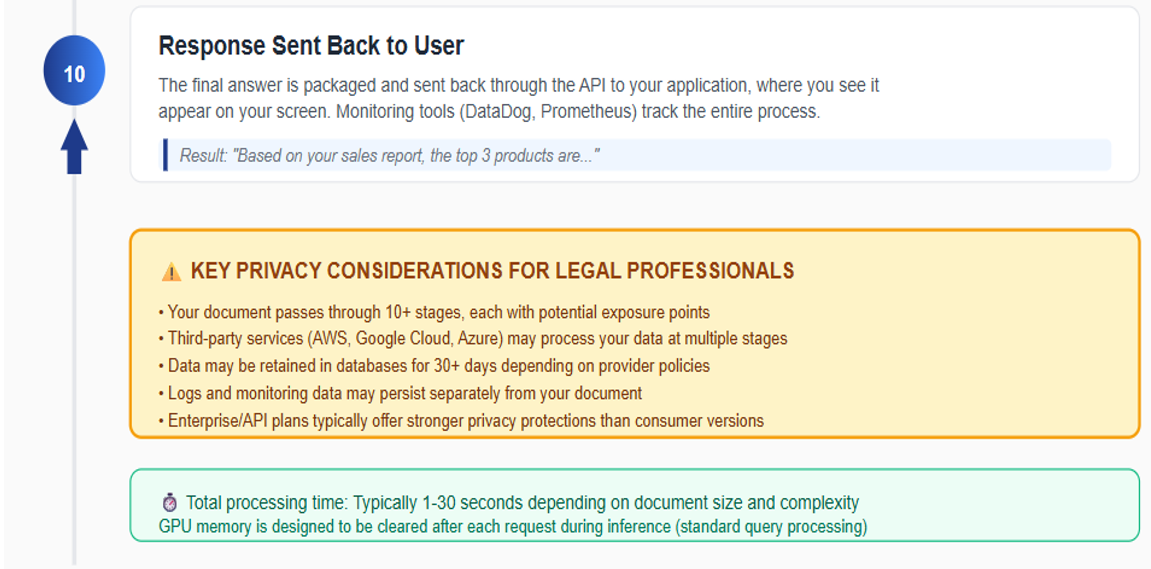
Data Retention Policies: Under most standard API plans, these systems typically retain your data for approximately 30 days; however, actual retention periods can vary depending on the provider and the specific service tier you select. Enterprise customers may have options for zero data retention (ZDR) or modified abuse monitoring. Throughout these stages, your client's confidential information is housed on servers outside your direct control, governed by the third-party provider's security protocols. This arrangement inherently carries the risk that, in the event of a data breach or insufficient safeguards, sensitive information could be exposed.
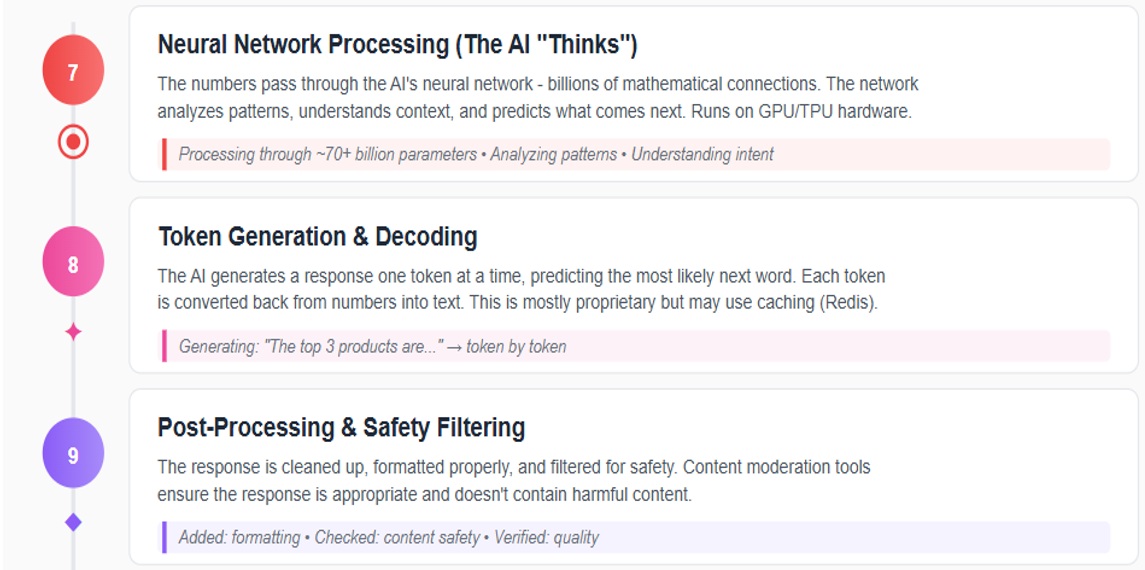
Stage 7: The AI Model Processes Your Document
Once your document reaches the AI provider's core infrastructure, it is processed by the underlying AI model such as OpenAI's GPT-4 or Anthropic's Claude. At this stage, the model reviews and analyzes the entire content of your document, including every word, number, and confidential detail. This analysis is performed in specialized hardware memory (typically GPU memory), which is designed to be cleared after your request is completed, minimizing the risk of residual data lingering in the system.
It is important to understand that, during standard query processing (known as inference), your document is not permanently stored within the AI model's internal knowledge base. In other words, the model does not "remember" your specific document after the response is generated. However, this separation is not absolute. Depending on the terms of your service agreement, there remains a possibility that your document could be retained and later used as part of the model's training data. If this occurs, elements of your client's confidential information may become incorporated into the model's broader knowledge, potentially surfacing in future outputs. This represents a significant ethical and practical risk and underscores the importance of reviewing provider policies and understanding exactly how your data may be used.
Stage 8-10: Response Generation and Logging
At the final stages of the AI processing pipeline, your document's content is transformed into a response through a series of advanced natural language processing (NLP) and machine learning (ML) operations. The AI system generates its answer incrementally—token by token—using sophisticated algorithms that predict and assemble the most relevant output based on your query and the processed document. This step-by-step generation allows the model to dynamically format the response, ensuring coherence and relevance.
Before the response is returned to your application, it passes through multiple safety and moderation filters. These filters are designed to detect and mitigate the inclusion of sensitive, inappropriate, or potentially harmful content. Providers typically employ a combination of proprietary algorithms and rule-based systems to flag or redact information that may violate privacy policies or ethical standards. For legal professionals, understanding these safeguards is crucial, as they directly impact the integrity and confidentiality of the information returned.
Once the response is finalized, it is transmitted back to your application via the provider's API. However, it is important to recognize that, throughout this process, most AI providers maintain detailed logs of each request and response. These logs serve several operational purposes, including debugging, system performance monitoring, and regulatory compliance. Technically, logs may capture metadata such as timestamps, user identifiers, and even excerpts or summaries of the processed document and generated response.
The retention period for these logs can vary widely—some providers may store logs for only a few days, while others may retain them for months or even years. Critically, these logs often exist outside the primary data processing environment and may not be subject to the same deletion or privacy controls as the original document. In the event of a security breach, audit, or subpoena, logged data could be accessed by parties beyond your control.
For legal professionals, these technical realities underscore the importance of thoroughly reviewing provider logging practices, retention policies, and access controls. By understanding how and where your client's information may be stored or exposed during the final stages of AI processing, you can better assess the long-term risks to confidentiality and make informed decisions about which AI services are appropriate for sensitive legal work. [See Figure 2]

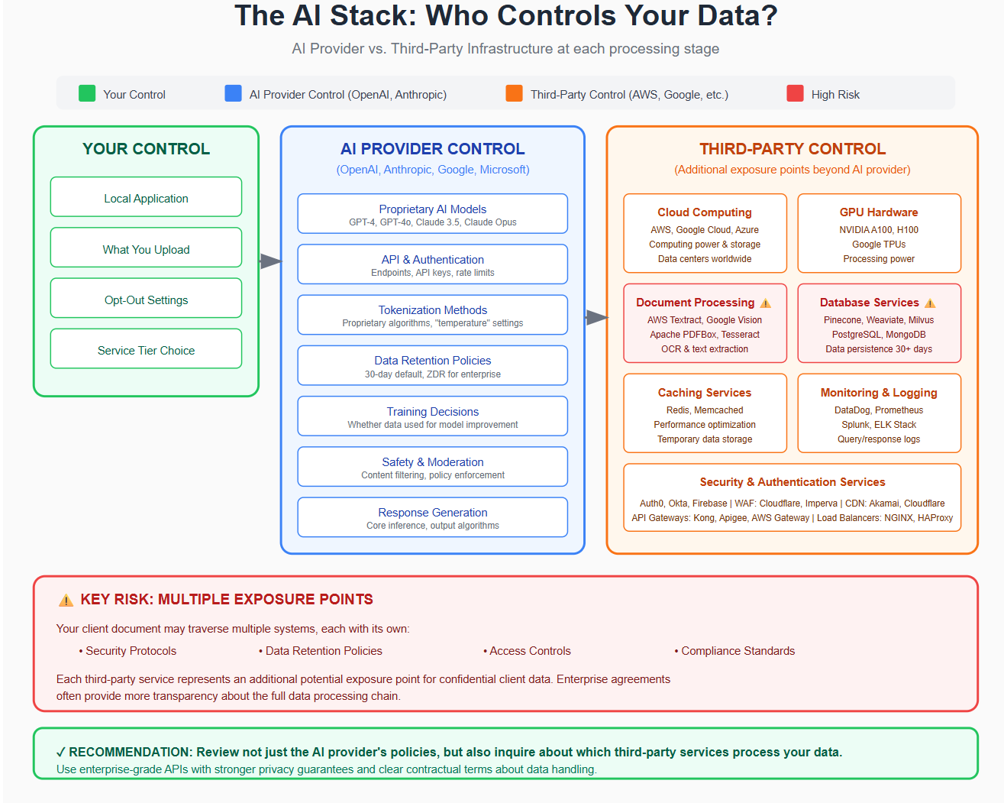
Who Controls the Infrastructure?
In some cases, the interfaces are also the AI service providers. They own and operate the AI models, control the infrastructure, and determine data usage policies. OpenAI and Anthropic exercise control over several critical aspects of their AI services. They own and operate the proprietary AI models—such as GPT-4 and GPT-4o for OpenAI, and Claude 3.5 Sonnet and Claude Opus for Anthropic—which represent significant investments in research and development. These providers also manage the processing pipeline, including API endpoints, authentication systems, tokenization methods, and response generation algorithms. Additionally, they determine data policies, such as how long data is retained, whether it is used for training, and under what circumstances it may be accessed. Safety and moderation, including content filtering and policy enforcement, also fall under their purview.
However, while OpenAI and Anthropic control the core AI technology, they still rely on third-party services for much of the supporting infrastructure. Cloud computing resources are provided by companies like Amazon Web Services (AWS), Google Cloud Platform, and Microsoft Azure, which supply the necessary computing power and storage. The hardware powering AI processing is typically NVIDIA.
Specialized tools—including PDF parsing libraries, optical character recognition (OCR) services, databases, and monitoring tools—are also provided by third parties, further expanding the ecosystem involved in AI data processing.
This creates additional exposure points. Your client document might be processed by AWS Textract for PDF text extraction or stored in databases hosted on Google Cloud. Each third-party service has its own security practices and data policies. [See Figure 3]
The Training Data Risk: When Your Client's Information Becomes Part of the AI System
With the AI pipeline stages and third-party control in mind, the next data security consideration is determining where the risk lies. This represents the most serious confidentiality risk. AI models are fundamentally shaped by the data they are trained on. When a client document is submitted to an AI service, there is a critical distinction between standard query processing (inference) and the process of model training. During inference, your document is analyzed to generate a response, but it is not supposed to be retained or incorporated into the model's long-term memory. However, depending on the provider's policies and the service tier you select, your document may be stored and later used as part of the model's training dataset.
If your client's confidential information is included in training data, it can become embedded within the AI's internal representations. This means that sensitive details—such as terms from a settlement agreement, personal identifiers, or privileged communications—could inadvertently influence future outputs generated for other users. In rare cases, fragments of confidential content may even be surfaced in responses to unrelated queries, posing a significant risk to client confidentiality and professional ethics.
The technical process involves aggregating large volumes of user data, which are then used to refine the AI's ability to understand language, generate accurate responses, and improve overall performance. Providers typically apply various data filtering and anonymization techniques, but these are not foolproof. For legal professionals, it is essential to understand whether your chosen AI service uses submitted documents for training, how long data is retained, and what safeguards are in place to prevent unauthorized disclosure.
To mitigate these risks, always review the provider's data usage and training policies, opt out of training data collection when possible, and consider using enterprise-grade or API-based services that offer stronger privacy guarantees. By taking these precautions, you can help ensure that your client's confidential information remains protected and is not inadvertently exposed through future AI interactions.
Understanding Security Certificates and What They Actually Mean
As AI services become increasingly integrated into legal practice, providers often highlight their security certifications, most commonly SOC 2 and ISO 27001, as evidence of robust data protection. While these certifications are important indicators of a provider's commitment to security, it is essential for legal professionals to understand both their scope and their limitations.
When evaluating AI providers for legal practice, it is essential to understand the significance and limitations of the security certifications commonly referenced in compliance charts. The most prevalent certifications include SOC 2 Type II, ISO 27001, HIPAA, GDPR, and attorney-client privilege awareness. SOC 2 Type II, developed by the American Institute of CPAs (AICPA), verifies that a provider has implemented and maintained effective controls for security, confidentiality, and privacy over a sustained period, typically six to twelve months.
Provider Compliance Certifications
GENERAL-PURPOSE APIs
| Provider | SOC 2 II | ISO 27001 | HIPAA | GDPR | Atty Privilege |
|---|---|---|---|---|---|
| Claude | ✓ | X | ✓ | ✓ | X |
| GPT-4 | ✓ | ✓ | ✓ | ✓ | X |
| Gemini | ✓ | ✓ | ✓ | ✓ | X |
| Copilot | ✓ | ✓ | ✓ | ✓ | X |
| Perplexity | ✓ | X | X | X | X |
| Grok | X | X | X | X | X |
LEGAL-SPECIFIC TOOLS
| Provider | SOC 2 II | ISO 27001 | HIPAA | GDPR | Atty Privilege |
|---|---|---|---|---|---|
| Spellbook | ✓ | ✗ | ✗ | ✗ | ✓ |
| CoCounsel | ✓ | ✗ | ✓ | ✗ | ✓ |
| Harvey AI | ✓ | ✗ | ✓ | ✗ | ✓ |
| Westlaw AI | ✓ | ✗ | ✓ | ✓ | ✓ |
| Paxton | ✓ | ✓ | ✓ | ✓ | ✗ |
While SOC 2 Type II and ISO 27001 certifications demonstrate commitment to data protection through independent audits, they do not guarantee immunity from breaches. More critically, neither certification addresses whether client data will be used for AI model training, retained beyond stated periods, or handled in compliance with legal ethics requirements such as attorney-client privilege protections.
HIPAA compliance is particularly relevant for matters involving protected health information, as it mandates strict privacy and security standards for handling sensitive patient data. GDPR, the European Union's data protection regulation, imposes rigorous requirements on data processing, retention, and user rights, making it indispensable for work involving EU clients. However, neither HIPAA nor GDPR guarantees compliance with U.S. legal ethics or attorney-client privilege.
Attorney-client privilege as an AI certification level refers to whether an AI platform or service is specifically designed to recognize, preserve, and protect the confidentiality of communications between attorneys and their clients. In the context of legal-specific AI tools, this means the provider has implemented technical and policy safeguards to ensure that any information processed by the platform is treated in accordance with the professional standards governing attorney-client privilege.
Unlike general-purpose AI platforms, which may not distinguish between ordinary business data and privileged legal communications, legal-specific AI tools (such as Spellbook, CoCounsel, Harvey AI, and Westlaw AI) are built to maintain the confidentiality required by law. This includes ensuring that client communications are not disclosed to unauthorized parties, preventing the use of privileged information for model training or other purposes that could compromise confidentiality, and providing contractual assurances and technical controls that align with legal ethics rules, such as ABA Model Rule 1.6.
The bottom line is that security certifications are a baseline requirement for any AI provider handling sensitive client information. However, they are not a substitute for understanding the provider's data usage, retention, and training policies. Always request documentation, ask pointed questions, and ensure that your chosen service aligns with your ethical obligations under Model Rule 1.6 and other applicable standards.
Legal-Specific AI Tools
When an AI provider lists "attorney-client privilege" as a certification or feature, it signals that the platform is purpose-built for legal professionals and incorporates additional protections beyond standard security certifications (like SOC 2 or ISO 27001). These protections are designed to help attorneys fulfill their ethical duty to safeguard client information and maintain privilege throughout the use of AI technology. While these tools cost 5-30x more than general solutions, they provide attorney-client privilege awareness, professional liability insurance coverage, and legal-specific training. Below are the top options available.
Spellbook: Spellbook is the most affordable legal-specific option, providing direct integration with Microsoft Word. It excels at contract drafting and analysis, making it ideal for firms where contract work is a primary use case. The platform maintains attorney-client privilege awareness and includes SOC 2 compliance. Perfect as a first step into legal-specific AI. As of this writing, Spellbook provides significant tools to improve efficiency for contracts, wills, and the like; however, it still struggles with correct case and pinpoint citations. Caution should be used when preparing pleadings and legal arguments.
CaseText CoCounsel: CoCounsel provides a full-featured legal AI platform built on the Thomson Reuters Casetext infrastructure. It combines legal research capabilities with advanced document analysis, making it suitable for firms that need both research and drafting support. Professional liability coverage and ABA compliance provide additional protection for legal work.
Harvey AI: Harvey AI represents the premium end of legal AI solutions, offering a complete platform with dedicated support and professional indemnification. It provides data isolation per firm, ensuring complete confidentiality of client work. Best for large firms with dedicated AI budgets and complex legal operations.
Westlaw AI: Westlaw AI provides seamless integration for firms already invested in the Westlaw ecosystem. It offers connected research capabilities that pull from the comprehensive Westlaw legal database, eliminating the need for separate platforms. Ideal for firms that want to extend their existing Westlaw investment with AI capabilities.
Paxton AI: Paxton AI is a comprehensive legal platform built on legal-specific training data with access to over 60 million legal documents. It specializes in accurate legal research with verified citations, contract review, and medical chronologies for personal injury cases. Paxton achieved a 94% accuracy rate on the Stanford legal hallucination benchmark—among the highest in the legal AI industry—and provides pinpoint accuracy for case law. The platform includes Microsoft Word integration and Boolean search capabilities for traditional legal researchers. Paxton AI is SOC 2 Type 2, HIPAA, and ISO 27001 certified. Again, as of this writing our use of Paxton has proven to be among the most accurate of the AI providers.
The Odd Duck: Microsoft 365
I suspect that most of us began using Microsoft as local desktop applications. However, Microsoft 365 has quietly transformed from a local desktop suite into a cloud-based ecosystem, changing how sensitive information is stored and managed. The security shift that came with the move to the cloud often went unnoticed. In Microsoft 365, files are automatically synced to OneDrive or SharePoint—meaning every confidential document resides on Microsoft's servers. Although Microsoft encrypts data in transit and at rest, client information ultimately exists outside your direct control. Many firms adopted Microsoft 365 for convenience without examining the security implications of this transition.
Additionally, the introduction of Microsoft Copilot adds new privacy concerns. Copilot can access documents, emails, and chats to generate responses, which means confidential data is processed on Microsoft's infrastructure. Microsoft explicitly states that "Prompts, responses, and data accessed through Microsoft Graph aren't used to train foundation LLMs, including those used by Microsoft 365 Copilot." However, the AI still interacts with potentially privileged information, and any document you can access, Copilot can access too. A single Copilot query could inadvertently expose data across multiple client matters if proper access controls are not in place.
Several Microsoft features may increase exposure risk. For example, version history and recovery retain deleted content for extended periods. Link sharing can unintentionally allow access to confidential files. Service agreements permit Microsoft to access data for compliance or security purposes, and third-party integrations create additional data access points. Many users overlook these issues because Microsoft 365 feels familiar and carries strong brand trust. But robust security controls—like Advanced Threat Protection, Data Loss Prevention, and Customer Lockbox—require higher licensing tiers (such as E5). Attorneys and firms should know what features their license includes, configure security settings appropriately, audit permissions regularly, and consider whether to limit Copilot's access to sensitive matters.
How to Protect Your Sensitive Documents
When using AI tools, understand how your data is handled. Enterprise APIs usually offer stronger privacy protections—data is not used for training and can often be deleted quickly—while free consumer versions may retain and train on your data. Always review the provider's policies and adjust settings to minimize risk.
Best practices generally include: redacting or anonymizing client identifiers; using synthetic data for tests or demonstrations; choosing enterprise or API plans with clear data retention limits; and avoiding unnecessary uploads of confidential material. Documents are most vulnerable when retained long-term, added to training datasets, or recorded in system logs. Before uploading sensitive data, ensure you fully understand where it will be stored, who can access it, and how long it will persist.
For highly sensitive information, self-hosted models may be preferable, though they require additional technical resources. It is also important to review each provider's privacy policies and ensure compliance with relevant regulations such as HIPAA, GDPR, and SOC 2. The bottom line is that your documents are exposed the moment you upload them to an AI service. Even reputable providers with strong privacy policies process your data through multiple systems, and depending on your service tier, your data could potentially be used for training. Before uploading sensitive documents, always read the provider's data usage policy, use API or enterprise plans for business purposes, opt out of training data collection where possible, and anonymize or redact confidential information to minimize risk.
Practical Guidance: Protecting Client Confidentiality in the Age of AI under Rule 1.6
Understanding the risks is only the first step. Following is some practical guidance for attorneys using AI tools while fulfilling their ethical obligations under Model Rule 1.6.
Risk Assessment
Before using any AI tool with client information, it is essential to conduct a thorough risk assessment. This involves evaluating the data sensitivity of the document to determine whether it contains trade secrets, privileged communications, personal identifying information (PII), or other highly sensitive data. You must also consider any regulatory requirements, such as whether you are subject to HIPAA, GDPR, state privacy laws, or industry-specific regulations. Additionally, consider your client's expectations by reviewing whether your engagement letter disclosed AI usage and whether your client would reasonably expect their information to be processed by third parties.
Selecting an AI Service
When selecting an AI service, it is important to understand that not all AI services are created equal, and your choice of service tier has significant implications for data privacy. API plans from providers like OpenAI API or Anthropic API offer better privacy protections, are typically not used for training, maintain standard 30-day retention periods, and are suitable for many legal applications when appropriate safeguards are in place. Enterprise plans provide the strongest guarantees, often including Business Associate Agreements (BAAs) for HIPAA compliance, immediate deletion options, enhanced security controls, and contractual commitments not to use data for training, making them the recommended choice for sensitive client information.
Reviewing Provider Policies
Once you have selected a service tier, you should carefully review and understand the provider's data policies. This means reading the data processing agreement, terms of service, and privacy policy, with specific attention to: data retention periods; training data policies; third-party service providers; data deletion procedures; security certifications such as SOC 2 and ISO 27001; and breach notification procedures. If the terms are unclear or concerning, you should contact the provider for clarification or consider alternative tools.
Data Minimization Strategies
Implementing data minimization strategies is crucial for reducing risk when using AI tools. You can achieve this by anonymizing information through removing or redacting names, addresses, social security numbers, account numbers, and other identifying information before uploading documents. For testing or training purposes, consider using synthetic data that has the same structure as real client information. You should also segment information by uploading only the specific sections relevant to your query rather than entire documents, and when possible, paraphrase confidential content by describing it in general terms instead of uploading the actual documents.
Opt Out of Training
For services that allow training data collection, it is critical to ensure this feature is disabled. In ChatGPT, for example, you can navigate to Settings, then Data Controls, and turn off the option to "Improve the model for everyone." Since settings can reset after updates or when switching devices, you should verify your opt-out status periodically.
Self-Hosted Alternatives
For highly sensitive matters, you may want to consider self-hosted alternatives where AI models run entirely on your firm's infrastructure. This approach could involve deploying open-source models like LLaMA or Mistral on your own servers or deploying models in your firm's private cloud environment. While self-hosted solutions require technical expertise and infrastructure investment, they provide maximum control over data.
Client Disclosure and Consent
Transparency with clients about AI usage is not just ethical—it is increasingly required. You should include disclosure in engagement letters to inform clients that you may use AI tools in your representation and explain the associated risks. For sensitive matters, obtain informed consent by getting explicit written consent before using AI tools with client information. It is also important to maintain written AI usage policies and ensure all attorneys and staff understand them.
Sample Engagement Letter Language: AI and Technology Disclosure
The following language is adapted from an actual engagement agreement and may serve as a template for firms seeking to disclose AI usage to clients:
"TECHNOLOGY SERVICES. We use Microsoft 365 as our primary platform, including Outlook for email, Word and Excel for documents, OneDrive and SharePoint for file storage, and Teams for video conferencing. Your communications and documents are stored on servers owned and operated by Microsoft Corporation, which may be located anywhere Microsoft operates globally. Microsoft has technical access to their systems for maintenance and security purposes and must comply with valid legal process such as subpoenas and court orders from government authorities. We do not have physical control over these servers and cannot prevent Microsoft from complying with their legal obligations.
We also use artificial intelligence tools including Claude by Anthropic, ChatGPT by OpenAI, and AI features within Microsoft 365 such as Copilot. We also use legal-specific AI tools such as Spellbook, Paxton, and Perplexity. We use these tools to assist with legal research, document drafting, contract analysis, and other legal tasks. We use only enterprise-grade AI services that contractually agree not to use our data for public model training. We redact identifying information when appropriate. All AI-generated content is reviewed and verified by our office for completeness and accuracy.
SECURITY AND LIMITATIONS. We select reputable providers with strong security certifications. We implement multi-factor authentication, access controls, and regular security training. Our providers use encryption and maintain security protocols. However, you should understand that no technology is completely secure. Technology services may experience security breaches, outages, or data loss despite safeguards. Providers must respond to legal process and government requests in their operating jurisdictions. We cannot guarantee absolute security or prevent all unauthorized access."
Ongoing Monitoring and Review
Because AI is a rapidly evolving field where policies, technologies, and risks change constantly, you must implement ongoing monitoring and review processes. This includes: conducting quarterly reviews of provider terms of service; subscribing to security alerts from your AI providers to monitor for breaches; tracking regulatory developments to stay informed about state bar opinions and guidance on AI usage; and periodically auditing which client information has been processed by AI tools.
Conclusion: Balancing Innovation and Ethics
Artificial intelligence offers tremendous potential for improving legal practice—enhancing efficiency, reducing costs, improving revenue, and democratizing access to legal services. However, these benefits come with responsibilities. As attorneys, we have an ethical duty to understand the tools we use and to protect our clients' confidential information.
The technical infrastructure behind AI tools is complex, but it need not be mysterious. By understanding where client documents travel, what happens to them at each stage, and what risks exist at various exposure points, attorneys can make informed decisions about AI usage.
The key principles are straightforward:
1. Understand the risks before uploading client information to any AI service
2. Choose appropriate service tiers based on data sensitivity
3. Minimize data exposure through anonymization and redaction
4. Verify security certifications but understand their limitations
5. Obtain client consent and maintain transparency
6. Stay informed as AI technology and policies evolve
Model Rule 1.6 requires that attorneys make reasonable efforts to prevent unauthorized disclosure of client information. In the context of AI tools, 'reasonable efforts' means understanding the technology, assessing risks, implementing appropriate safeguards, and being transparent with clients. It does not necessarily mean avoiding AI entirely—but it does mean using these tools thoughtfully and responsibly.
The visualizations accompanying this article provide an accessible way to explore these concepts in greater depth. We encourage readers to review them and to share this information with colleagues. As AI becomes increasingly integrated into legal practice, education and awareness are our first lines of defense in protecting client confidentiality.
The legal profession has always had to adapt to new technologies while maintaining its core ethical commitments. AI is no exception. By approaching these tools with both curiosity and caution, we can harness their benefits while upholding our fundamental duty to our clients.
About the Author:
David M. Fogg is the founder and principal attorney of Cornerstone Tech and Estate Advisors, PLLC, a forward-thinking law firm licensed in Idaho, Washington, and Arizona. Before entering the legal profession, David built a distinguished four-decade career in engineering and technology — beginning with aerospace work on the F-16 aircraft at General Dynamics and networking standards development at Johns Hopkins Applied Physics Laboratory, through senior roles at IBM where he served as Hot Process Best of Breed Equipment Manager and as an IBM assignee to the SEMATECH consortium in Austin, Texas, contributing to the industry-defining Standardized Supplier Quality Assessment (SSQA) program. His technical career culminated as Director of Engineering and Manufacturing for IBM's Semiconductor BAT facility in Singapore, followed by his tenure as CEO of Nano Silicon Technologies, Ltd.
After earning his Juris Doctorate from the University of Idaho in 2007, David brought that depth of technical and executive experience to the practice of law. He currently chairs the Technology and Management Bar Section of the Idaho State Bar, with a significant focus on machine learning, artificial intelligence, and large language models, and serves on the Technology Working Group of the Arizona State Bar. At Cornerstone, his practice centers on business law, estate planning, real estate, and technology matters, with a commitment to reimagining legal services through the same spirit of innovation that defined his engineering career.
David M. Fogg can be reached at admin@cornerstonetea.com.
Additional Resources
Provider Documentation
• OpenAI API Data Usage Policy: https://openai.com/enterprise-privacy
• Anthropic Privacy Policy: https://www.anthropic.com/legal/privacy
• OpenAI Terms of Use: https://openai.com/policies/terms-of-use
• Anthropic Commercial Terms: https://www.anthropic.com/legal/commercial-terms
Ethics and Professional Responsibility
• ABA Model Rule 1.6: Confidentiality of Information
• ABA Formal Opinion 477R: Securing Communication of Protected Client Information (2017)
• ABA Formal Opinion 512: Generative Artificial Intelligence Tools (July 2024)
• ABA Task Force on Law and Artificial Intelligence: https://www.americanbar.org/groups/centers_commissions/center-for-innovation/artificial-intelligence/
• State bar ethics opinions on AI usage (check your jurisdiction)
Technical Background
• NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
• ISO/IEC 42001: AI Management Systems
Disclaimer: This article provides general information about AI systems and data privacy considerations. It should not be construed as legal advice. AI technologies and provider policies change rapidly. Always consult current terms of service, privacy policies, and applicable ethics rules in your jurisdiction before using AI tools with client information. State bar rules may impose additional or different requirements; readers should consult their jurisdiction's specific guidance.
References:
[1] ABA Model Rules of Professional Conduct, Rule 1.6(c) (2023). Available at: https://www.americanbar.org/groups/professional_responsibility/publications/model_rules_of_professional_conduct/rule_1_6_confidentiality_of_information/. The rule was amended in 2012 following the Ethics 20/20 Commission's recommendations to address technology-related confidentiality obligations.
[2] ABA Standing Committee on Ethics and Professional Responsibility, Formal Opinion 477R (Revised May 22, 2017), "Securing Communication of Protected Client Information." This opinion updated Formal Opinion 99-413 and addresses lawyers' obligations when transmitting confidential information over the internet.
[3] ABA Standing Committee on Ethics and Professional Responsibility, Formal Opinion 512 (July 29, 2024), "Generative Artificial Intelligence Tools." This opinion addresses lawyers' ethical obligations when using generative AI in practice. Additional resources available at: https://www.americanbar.org/groups/centers_commissions/center-for-innovation/artificial-intelligence/
[4] American Institute of Certified Public Accountants (AICPA), SOC 2® - SOC for Service Organizations: Trust Services Criteria. SOC 2 Type II reports evaluate both the design and operating effectiveness of controls over a period typically ranging from 3-12 months.
[5] OpenAI, "Data controls in the OpenAI platform" and "Enterprise privacy at OpenAI." Documentation confirms: "By default, abuse monitoring logs are generated for all API feature usage and retained for up to 30 days." Zero Data Retention (ZDR) is available for eligible enterprise customers. Available at: https://platform.openai.com/docs/guides/your-data
[6] Microsoft, "Data, Privacy, and Security for Microsoft 365 Copilot." Documentation states: "Prompts, responses, and data accessed through Microsoft Graph aren't used to train foundation LLMs, including those used by Microsoft 365 Copilot." Available at: https://learn.microsoft.com/en-us/copilot/microsoft-365/microsoft-365-copilot-privacy
[7] Paxton AI, "Paxton AI Releases Benchmarking Data Showing 94% Accuracy" (July 2024). The Stanford legal hallucination benchmarks showed Paxton achieved a 94.7% non-hallucination rate and 93.82% accuracy. Available at: https://www.lawnext.com/2024/07/paxton-ai-releases-benchmarking-data-showing-94-accuracy-of-its-legal-research-tool-also-releases-new-confidence-indicator-feature.html
[8] General principle of AI inference processing. GPU memory management during inference is a standard practice where memory is allocated for processing and released after completion.
[9] AWS Textract, Google Cloud Vision, and Apache PDFBox are widely used document processing tools. AI providers commonly use third-party services for document extraction, though specific implementations vary.
